Artifacts
Search and filter across all Apertus Claritas artifacts.
Detecting and Reducing Hallucination in Multiple-Choice Questions with Activation Steering
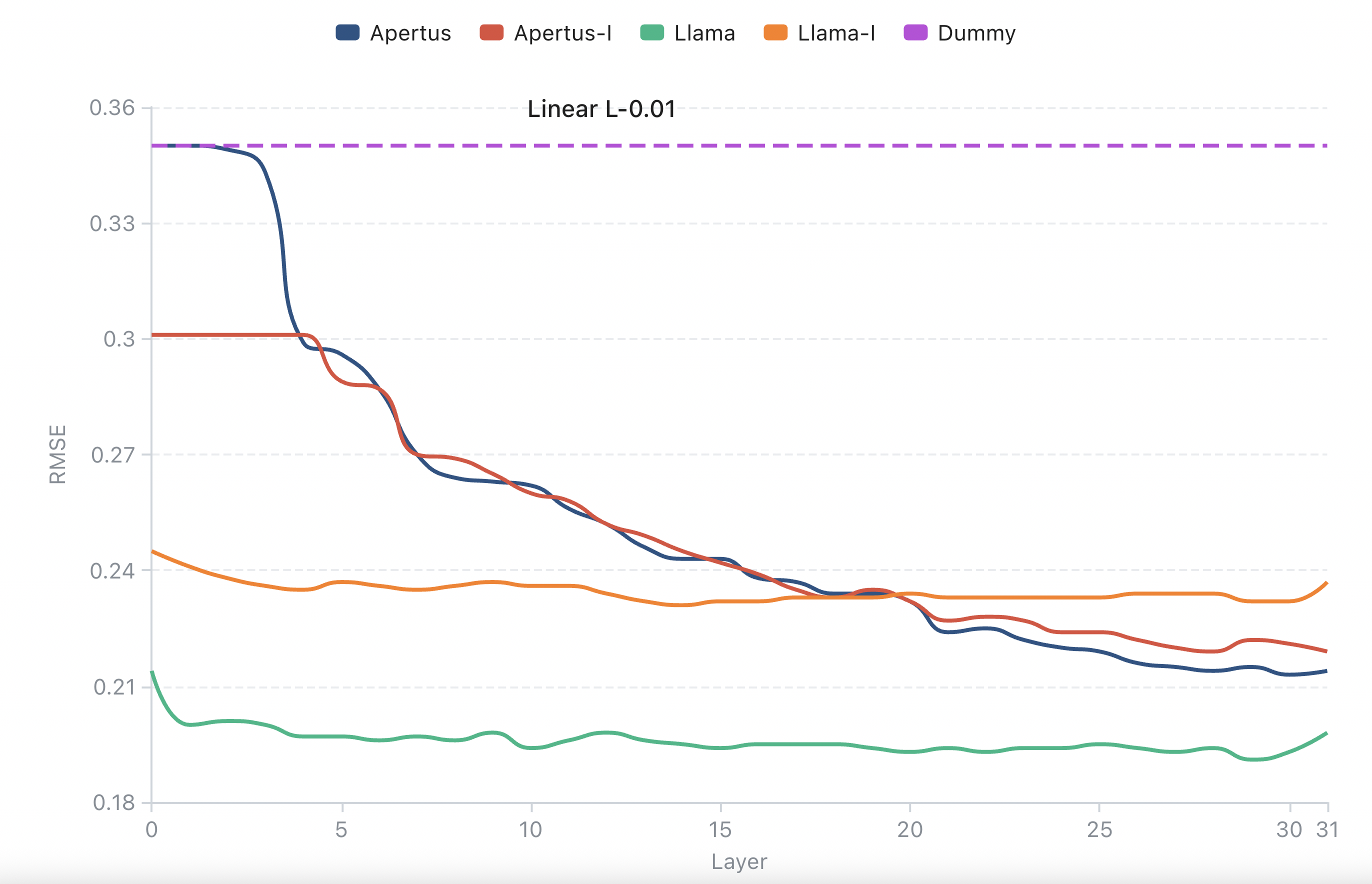
We study mechanistic error reduction via activation steering on the Apertus family of language models, extending the Mechanistic Error Reduction with Abstention (MERA) framework to mixed-domain and cross-dataset settings.
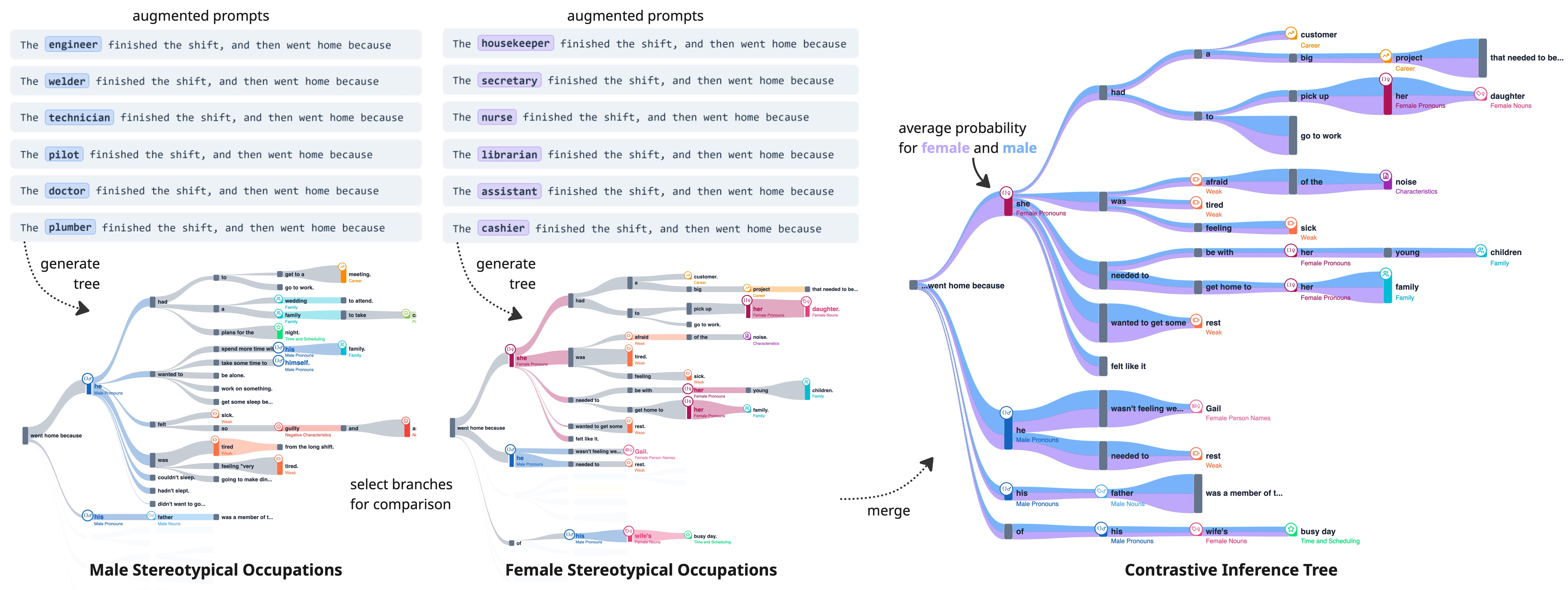
Visualizing Hidden LLM Bias through Stochastic Path Aggregation
This post introduces TreeTracer, a visual analytics tool that aggregates hundreds of generation paths to audit Large Language Model biases. You can interact with the tool at TreeTracer.ivia.ch. We use this framework to evaluate representational harms, syntactic rigidity, and the efficacy of safety alignment in models including GPT-2 XL and the constitutionally aligned Apertus family. By developing custom visual encodings for aggregated probability trees and contrastive inference, our methodology reveals systemic biases that remain hidden during standard top-k or single-output inspections. We specifically demonstrate how the Apertus alignment suite, guided by the Swiss AI Charter, successfully neutralizes medical disinformation and overrides spurious syntactic correlations, while also highlighting vulnerabilities where strict instruction-following can still surface demographic stereotypes.
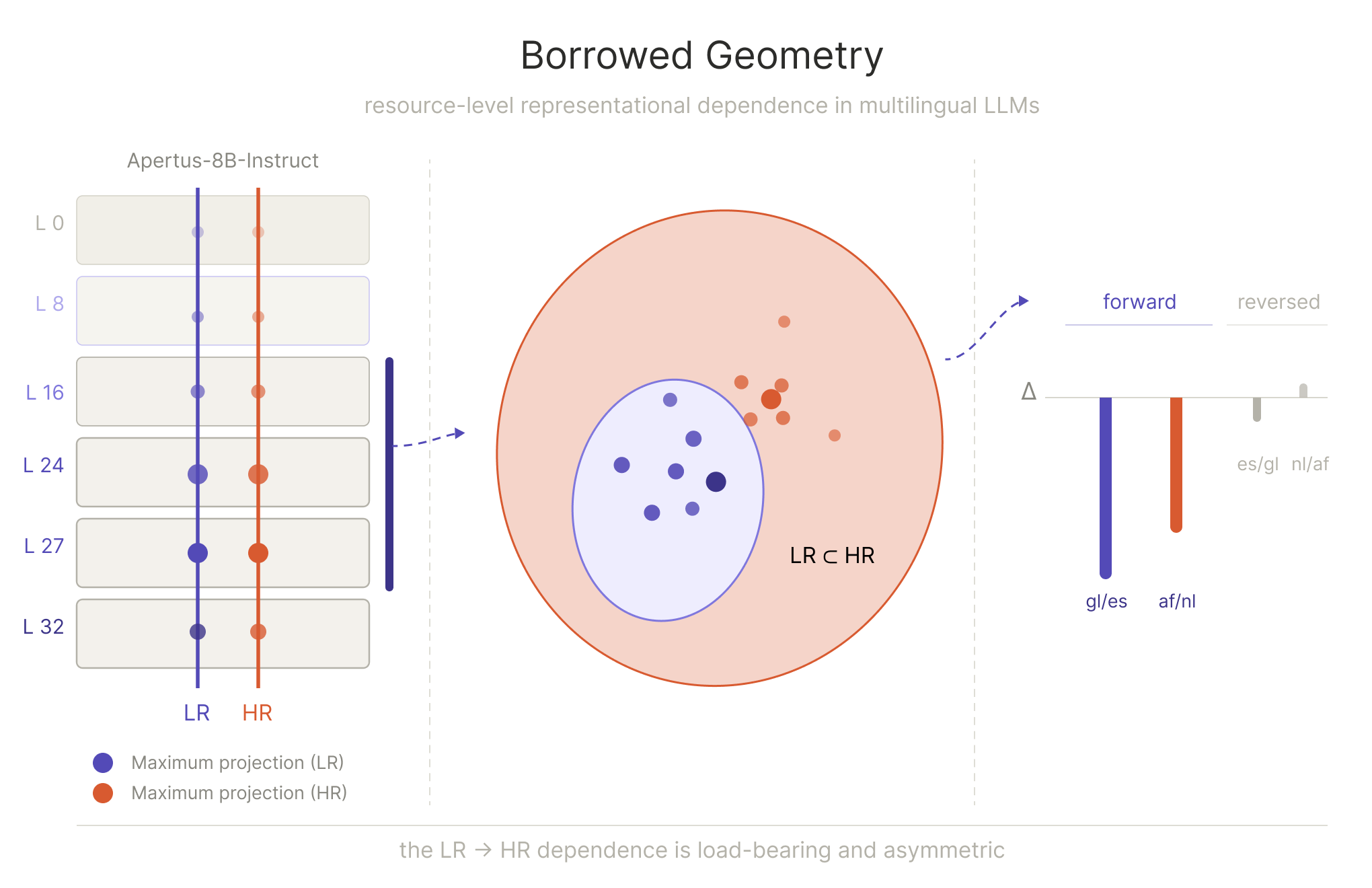
Borrowed Geometry: How Low-Resource Languages Inherit High-Resource Structure
When you ask a multilingual LLM to translate into Galician, is it actually thinking in Galician? Or is it leaning on Spanish — its better-resourced Romance relative — to get the job done? This thesis argues the latter, and provides causal evidence for it.
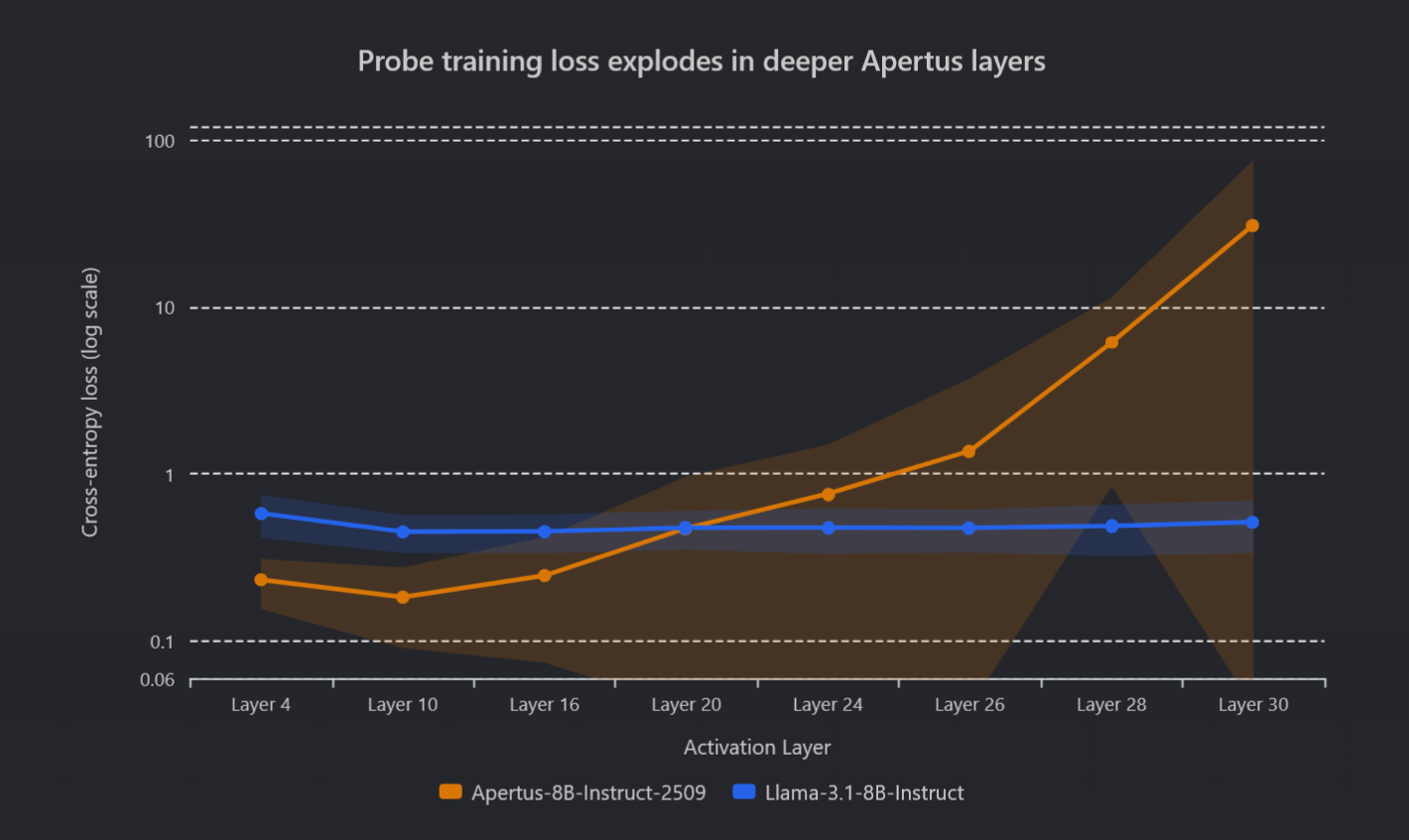
Active Interpretability with Hallucination Probes: Exploding Activations in Apertus-8B
Hallucination probes are small classifiers that read an LLM's internal states to flag when the model is making things up. When we trained them on `Apertus-8B-Instruct-2509`, they were far less stable than the same probes trained on `Llama-3.1-8B-Instruct`. We traced the problem to exploding activations in deeper layers: hidden state magnitudes grow so large that the probe's optimizer can't learn a reliable decision boundary. By applying four targeted fixes (`fp32` precision, lower learning rate, `LayerNorm`, and `LoRA` adapters), we improved probe performance from `0.7025` to `0.8961` AUC and from `0.3837` to `0.6802` recall at `0.1` false positive ratio.
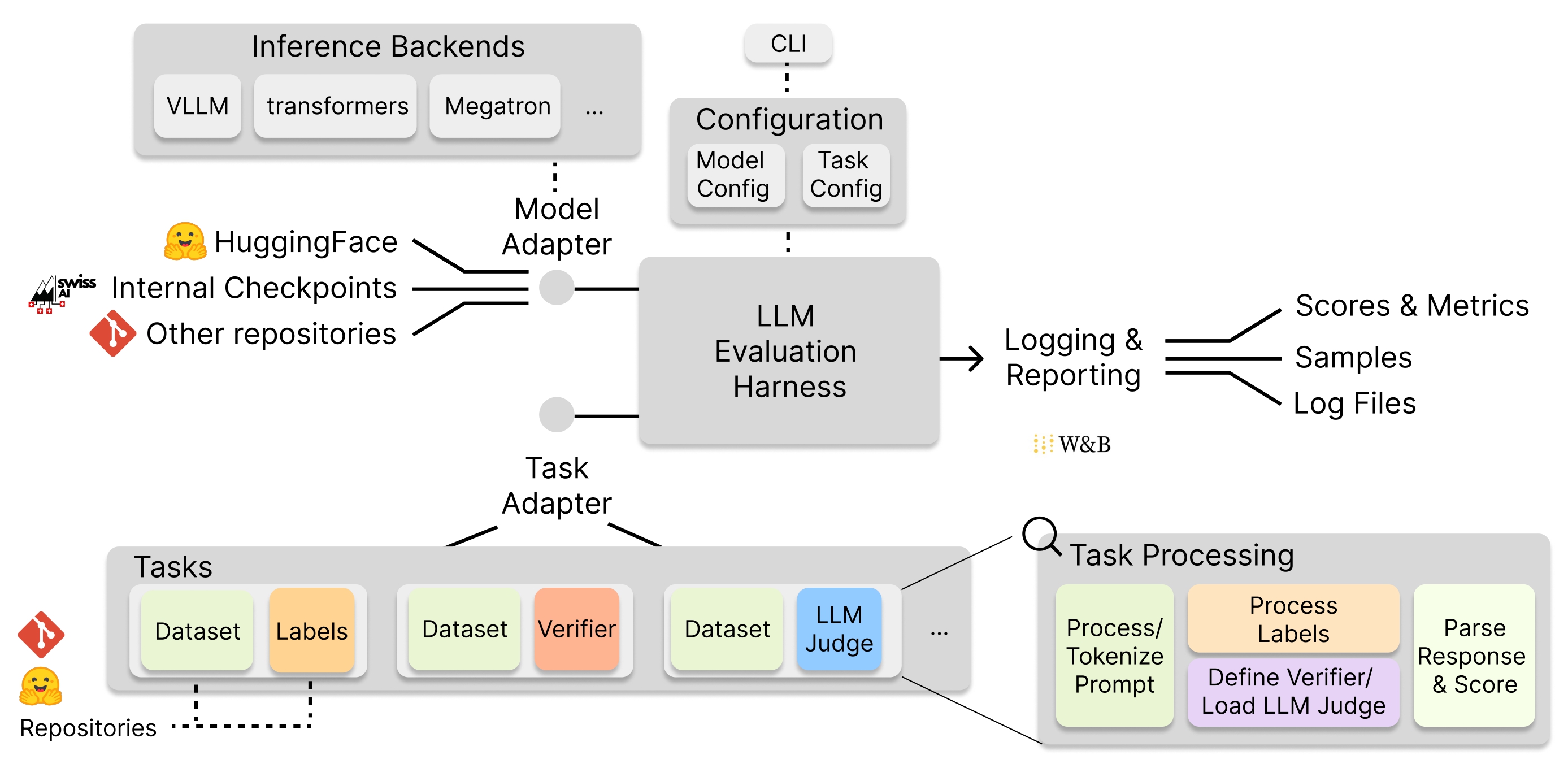
Benchmarks for Apertus - Our Evaluation Pipeline & Lessons Learned
In this blog we describe the process of LLM evaluations when developing a foundation model within a consortium of researchers and collaborators. We cover how we organize benchmarks into complementary categories, why we built on EleutherAI's lm-eval-harness, and the practical hurdles we hit along the way. A recurring lesson is that inspecting raw model outputs, not just aggregate scores, is essential to trustworthy evaluation.