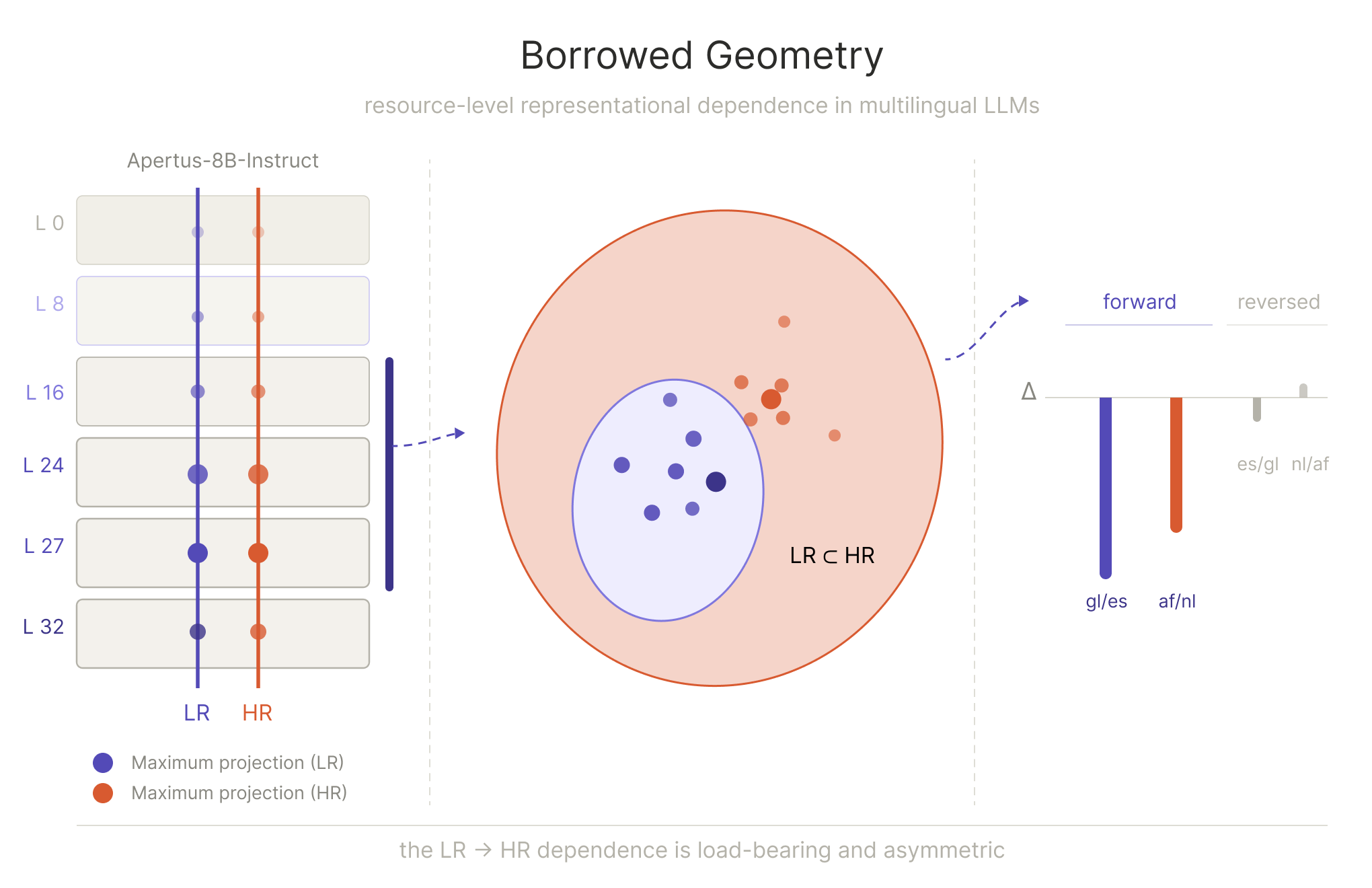
Borrowed Geometry: How Low-Resource Languages Inherit High-Resource Structure in Multilingual LLMs
Arundhati Balasubramaniam — Master's Thesis, ETH Zürich / EPFL, April 2026
Supervised by Prof. Dr. Daniel Gatica-Perez and Prof. Dr. Mennatallah El-Assady (EPFL/ETH Zürich), with Dr. Rita Sevastjanova and Dr. Anna Hedström (Swiss AI Initiative).
When you ask a multilingual LLM to translate into Galician, is it actually thinking in Galician? Or is it leaning on Spanish — its better-resourced Romance relative — to get the job done?
This post summarises my master's thesis, which argues the latter, and provides causal evidence for it. The full thesis is available here. The experiments were run on `Apertus-8B-Instruct-2509`, a Swiss open multilingual model developed by the Swiss AI Initiative, on the Clariden HPC cluster at CSCS.
1. The Problem
Low-resource languages aren't just underserved by LLMs — they may be structurally dependent on their high-resource relatives in ways that are geometrically expressible and causally consequential.
We know that English dominates pretraining data (over 90% for the Llama family). We know that low-resource languages underperform on benchmarks. What we don't know is why, at a mechanistic level. Is it just data scarcity? Or does the model develop a specific geometric scaffold in which Galician borrows structure from Spanish, and Afrikaans borrows from Dutch — even when the model was explicitly trained to be multilingual?
This is the stepping-stone hypothesis, and it is the central claim of this thesis.
2. The Hypothesis
Low-resource language representations in multilingual LLMs are geometrically contained within the subspace of their high-resource family relatives — and this containment is load-bearing for downstream generation quality.
We study two independent language families, chosen to provide a clean resource gradient within each family and to allow cross-family replication:
- Ibero-Romance: Spanish (high) ≻ Catalan (medium) ≻ Galician (low)
- West-Germanic: German (high) ≻ Dutch (medium) ≻ Afrikaans (low)
The model throughout is `Apertus-8B-Instruct-2509`, a Swiss multilingual LLM with approximately 40% non-English pretraining coverage. The choice of Apertus-8B-Instruct-2509 over English-centric alternatives like Llama-2 is deliberate: a model where non-English languages account for less than 10% of pretraining would conflate any within-family stepping-stone signal with English-pivot artefacts, making it impossible to isolate the effect we are looking for.
The stepping-stone hypothesis has two components.
Geometric claim. In late transformer layers, the hidden states of a low-resource language (LR) should project more strongly onto the contrastive axis of a related high-resource language (HR) than vice versa. Formally:
Causal claim. The geometric dependence is not merely a representational artefact — it is functionally necessary for generation quality. Surgically suppressing the high-resource directional component from low-resource hidden states during generation should degrade translation quality. The reversed intervention — suppressing the low-resource direction from high-resource hidden states — should produce near-zero effect.
3. What's Different from Prior Work
The English-pivot hypothesis (Wendler et al., 2024) shows that multilingual LLMs route representations through an English-dominant subspace during generation. We accept this finding. The stepping-stone hypothesis does not replace it — it adds a finer-grained, within-family layer of scaffolding on top of it.
Our contribution. We propose that Galician depends not only on English as a global pivot, but also on Spanish as its closest high-resource relative within the Romance family. The stepping-stone relationship is within-family, resource-ordered, and — crucially — causally testable via projection ablation.
To our knowledge, no prior work had asked whether the geometric relationship between two related languages is (a) directional, (b) resource-ordered within a genealogical family, or (c) causally necessary for generation quality. The table below shows how the key prior works relate to these three questions.
| Work | Method | Gap |
|---|---|---|
| Chang et al., 2022 | Layer-wise geometric analysis, XLM-R, 88 languages | Symmetric treatment; no resource ordering; no causal test |
| Wendler et al., 2024 | Logit lens language tracking, LLaMA-2 | English-only pivot; no within-family dependence |
| Wu et al., 2025 | Semantic hub via cosine similarity | English-centric; no genealogical pairs; no asymmetry index |
| Bajwa, 2025 | Single-direction ablation, Urdu–English | One pair; no family controls; no asymmetry test |
| Lasnier et al., 2026 | Activation patching; attention head decomposition | Head-level; no genealogical pairs; no containment framing |
| This work | Contrastive axis projection; causal ablation; dose-response sweep | First causal test of directional, resource-ordered within-family geometric dependence |
4. The Method
The pipeline proceeds in four stages: hidden state extraction, geometric analysis, layer selection, and causal ablation. We describe each in turn.
Contrastive axis construction. For each language L at each transformer layer ℓ, we construct a contrastive reference vector as the normalised difference between the mean hidden state of language L and the mean hidden state of English, computed over neutral sentence-completion prompts. The prompt for Spanish, for example, takes the form:
Continúa la siguiente oración: [sentence]
Subtracting the English reference isolates the language-specific direction and prevents the high-resource axis from collapsing onto a generic cross-lingual direction common to all languages. The resulting contrastive axis is:
where denotes the ℓ₂-normalised mean reference vector at layer ℓ, computed over N = 50 high-quality sentences.
Layer selection. Not all layers carry the same stepping-stone signal. We restrict attention to the second half of the network (ℓ ≥ 16), consistent with prior work showing that language-specific structure consolidates in late transformer layers (Wendler et al., 2024). Within this range, a layer is selected if its mean projection magnitude exceeds the second-half mean by at least 0.25 standard deviations. Taking the intersection across within-family pairs ensures that selected layers are consistent across the family rather than idiosyncratic to a single pair. The result:
- Romance family: S_IR = {25, 27} (where IR stands for Ibero-Romance)
- Germanic family: S_WG = {27, 28, 31} (where WG stands for West-Germanic)
Layer 27 appears in both family intersections — a cross-family consistency suggesting it is a general locus of high-resource representational influence in the Apertus-8B-Instruct-2509 architecture.
Projection ablation. At each selected layer, we apply a surgical intervention to low-resource hidden states during generation. Specifically, we remove the component of the hidden state that aligns with the high-resource contrastive axis:
The suppression strength α is swept across {0.1, 0.2, 0.3, 0.4, 0.5}. A monotonically degrading dose-response curve is a stronger claim than any single binary comparison — if the stepping-stone direction is genuinely load-bearing, each increment of α should produce a further quality drop. The method requires no model fine-tuning or architectural modification and is implemented as a PyTorch forward hook on the residual stream.
Evaluation. Translation quality is measured with `wmt22-cometkiwi-da`, a reference-free neural quality estimation metric (Rei et al., 2022). All effects are reported as Δ COMET-Kiwi relative to an unhooked none baseline generated under identical conditions, controlling for sentence difficulty and generation stochasticity. The source corpus is `CoVoST 2` (Wang et al., 2021), filtered to N = 5,000 sentences stratified by syntactic complexity.
5. Results
5.1 Verifying the Representational Signal
Before intervening on anything, we first verify that the hidden states actually carry quality-relevant structure. We train linear logistic regression probes on the hidden states at each of the 33 transformer layers of Apertus-8B-Instruct-2509, using 5-fold stratified cross-validation, to predict whether a given translation belongs to the high-quality or low-quality group. This follows the probing methodology of Alain and Bengio (2018) — if a simple linear boundary can separate the groups, quality information is considered linearly decodable from that layer's representations.
All six languages exceed 0.80 probe accuracy well above the 0.50 chance baseline, confirming that the hidden states carry a quality signal worth acting on. This suggests that the subsequent projection and ablation analyses have a representational basis.
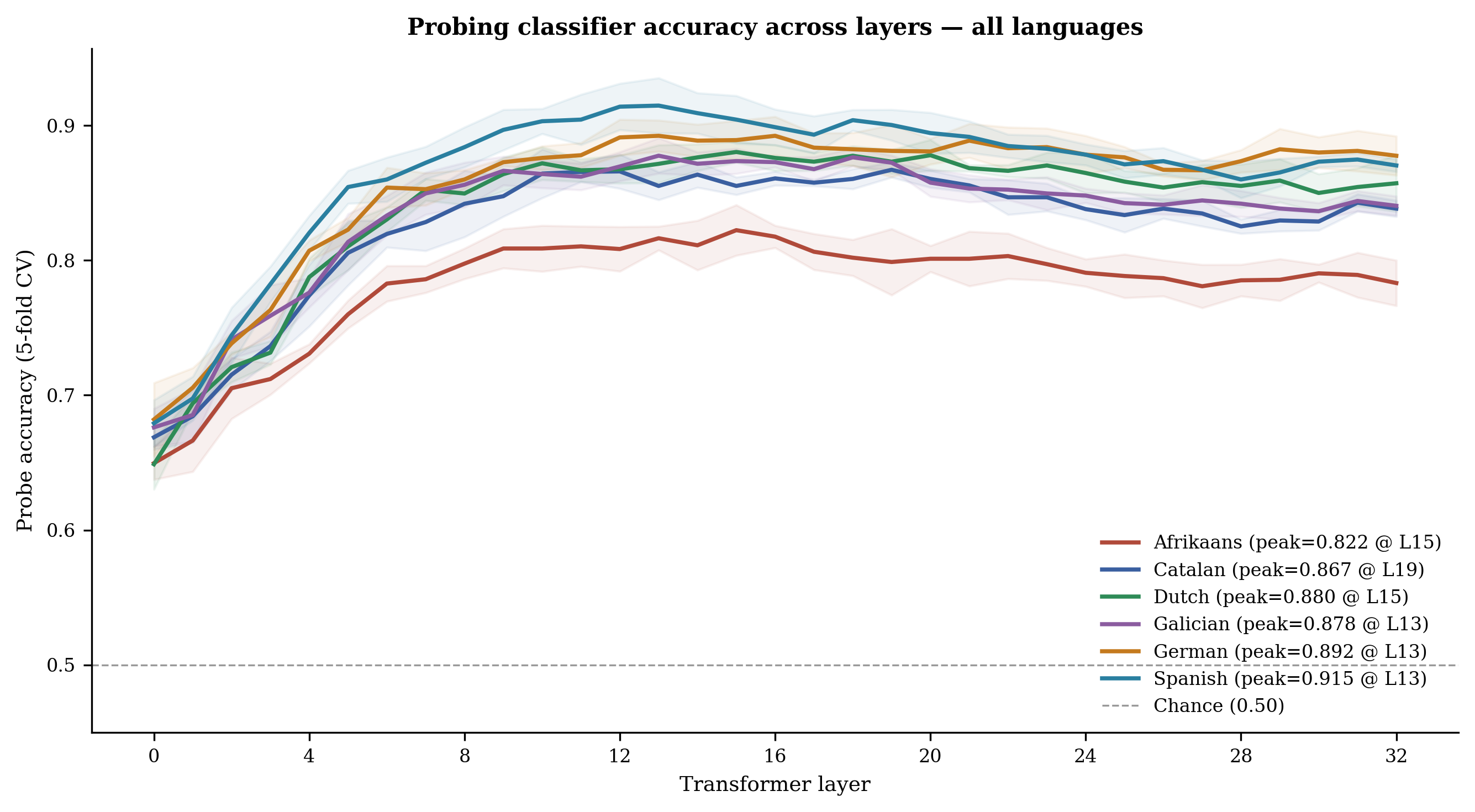
Notably, Afrikaans is a clear outlier, with a substantially lower peak accuracy (0.822 at L15) and wider confidence bands than all other languages. This is consistent with the stepping-stone hypothesis: if Afrikaans representations depend heavily on Dutch/German structure rather than encoding quality information in a distinctively Afrikaans direction, a linear classifier operating on raw hidden states would find them harder to classify.
5.2 Layer-Wise Projection Magnitude
Next, we examine how strongly each language's hidden states project onto the high-resource contrastive axis at each layer. Both families show the same qualitative pattern: near-zero projection magnitude in early layers, gradual rise through the middle of the network, then steep and uneven growth in the final layers. The sharp increase above L16 motivates the restriction of layer selection to the second half of the network.
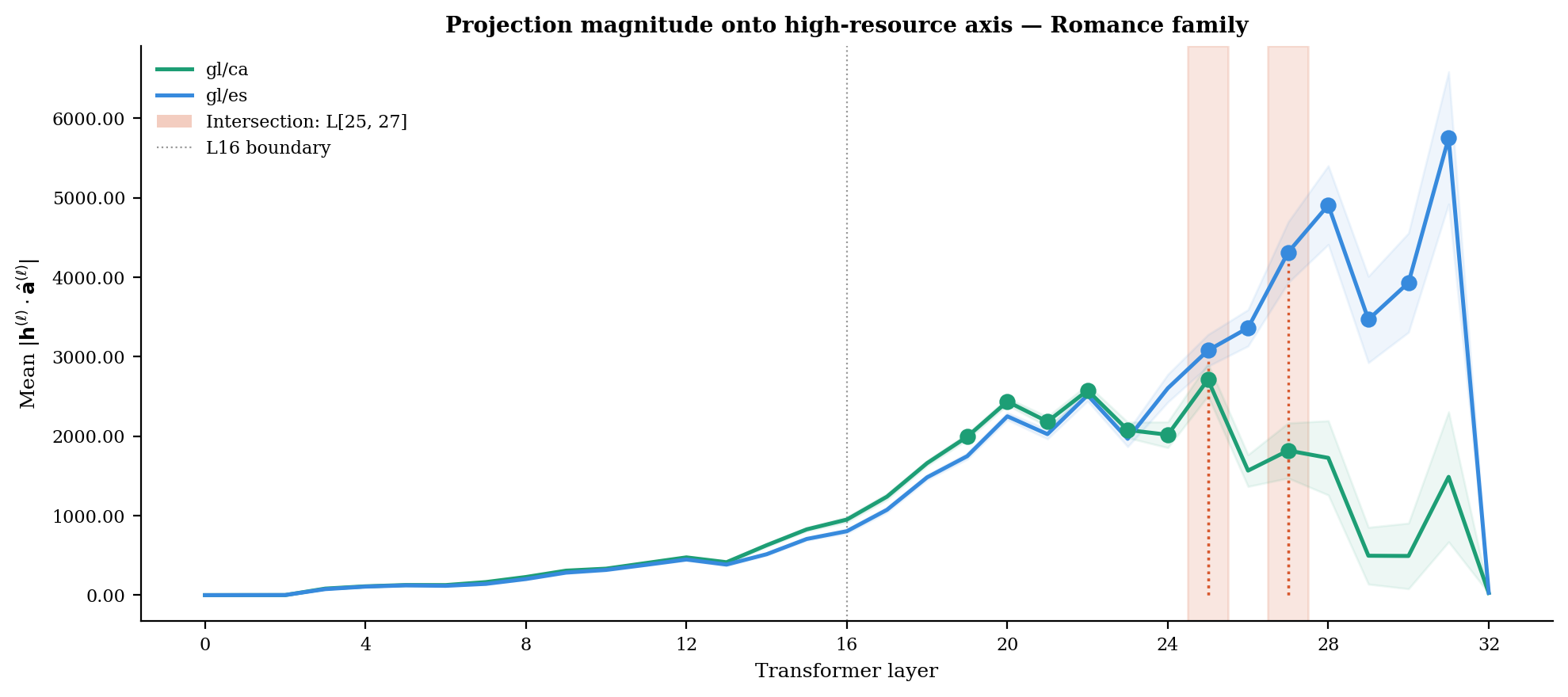
Within the Romance family, the gl/es pair reaches substantially higher late-layer projection magnitudes than gl/ca — Galician aligns more strongly with Spanish (~5700 at L32) than with Catalan (~2700 at L25). This difference is consistent with the stepping-stone hypothesis predicting stronger alignment with the primary high-resource language than with the medium-resource one.
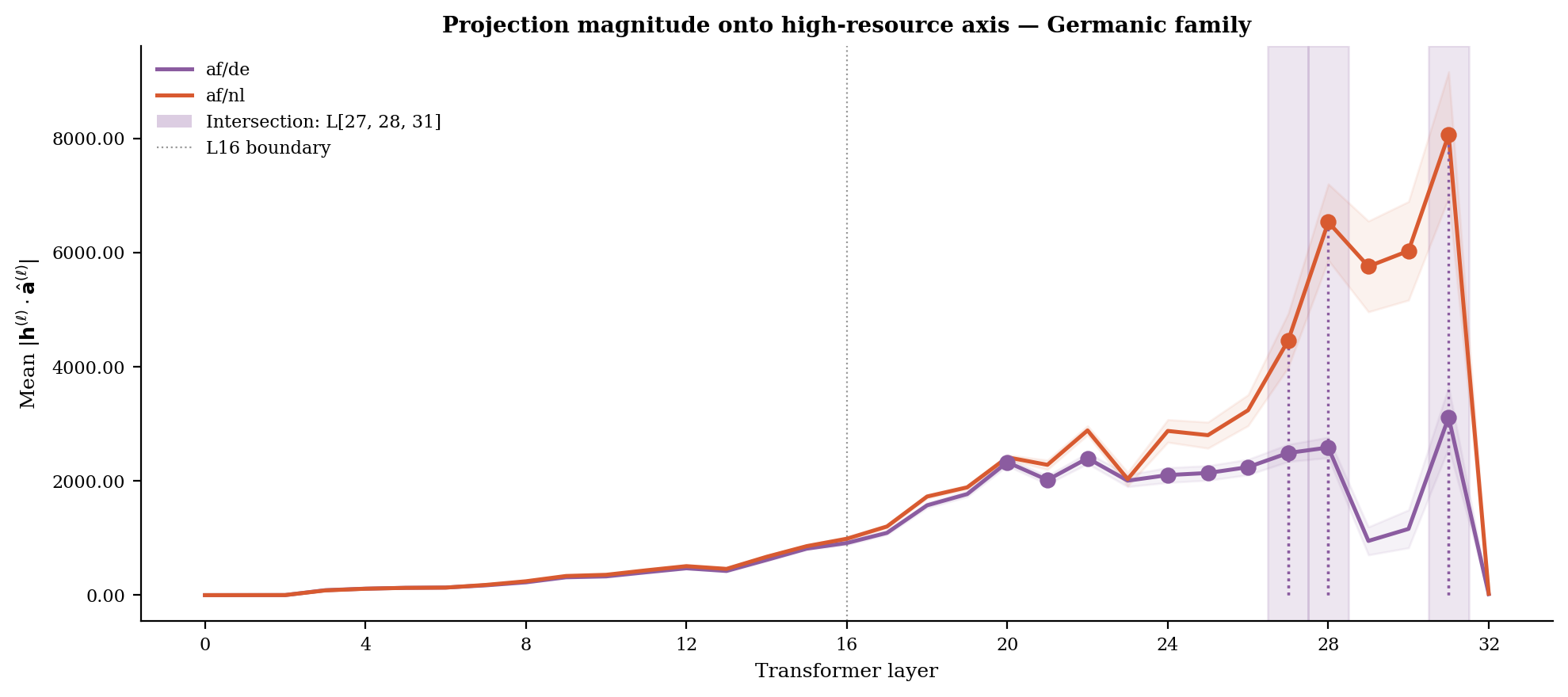
Within the Germanic family af/nl similarly outpaces af/de in late layers, peaking at approximately 8100 at L31 versus 3100 for af/de. In both families, the resource ordering of projection magnitudes matches the resource ordering of the languages — suggesting the geometry is not arbitrary but tracks training data asymmetry.
5.3 Subspace Containment
To characterise the directional asymmetry more directly, we compute the mean language identity score — the normalised projection of hidden states onto the contrastive axis — over all layers ℓ ≥ 16. The asymmetry index Δρ = ρ(src→axis) − ρ(axis→src) captures whether the source language is more contained within the axis language's subspace than vice versa.
| Pair | ρ_src→axis | ρ_axis→src | Δρ |
|---|---|---|---|
| gl/es | 0.675 | 0.568 | +0.107 |
| gl/ca | 0.617 | 0.535 | +0.082 |
| es/ca | 0.596 | 0.598 | −0.002 |
| af/nl | 0.512 | 0.546 | −0.035 |
| af/de | 0.449 | 0.460 | −0.011 |
The Romance family shows clear directional asymmetry: Galician is more contained within Spanish space (Δρ = +0.107) than Spanish is within Galician space. The es/ca pair shows near-zero Δρ, consistent with Spanish and Catalan occupying comparable representational positions without a clear stepping-stone relationship. This suggests the asymmetry tracks resource level, not merely language similarity.
The Germanic family shows smaller and slightly negative Δρ values — a mixed picture for the containment measure. This is not necessarily contradictory: the containment measure and the projection profiles capture slightly different aspects of the geometric relationship, and the greater structural distance between Afrikaans and Dutch/German compared to the Ibero-Romance family may reduce the containment signal. The causal ablation, described next, is the stronger and more direct test.
5.4 Step 4: Causal Ablation — Dose-Response
We now turn to the central experiment: does suppressing the high-resource direction from low-resource hidden states actually degrade translation quality? The forward ablation results are as follows, at maximum suppression α = 0.5:
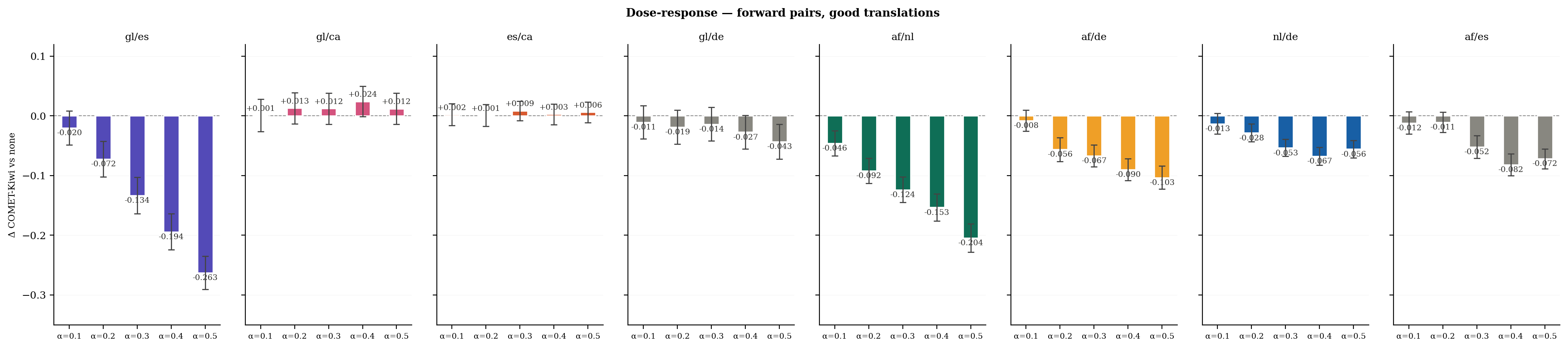
All primary pairs show clean monotonic degradation — each increment of α produces a further quality drop, with no threshold effects or reversals. For Galician, suppressing the Spanish axis causes the model to lose more than a quarter of a COMET-Kiwi point relative to the unhooked baseline. This suggests that the Spanish directional component is not incidental to Galician generation — removing it measurably and progressively harms output quality.
By contrast, the within-family null control gl/ca remains flat across all α values. This confirms the effect is axis-specific: the degradation for gl/es is not a generic consequence of suppressing any Romance-family direction at the selected layers, but is specific to the Spanish axis.
5.5 Step 5: Causal Ablation — Forward vs. Reversed Asymmetry
The dose-response result establishes that the forward ablation degrades quality. But the critical test is whether the reversed intervention — suppressing the Galician direction from Spanish hidden states — produces a comparable effect. The stepping-stone hypothesis predicts it should not.
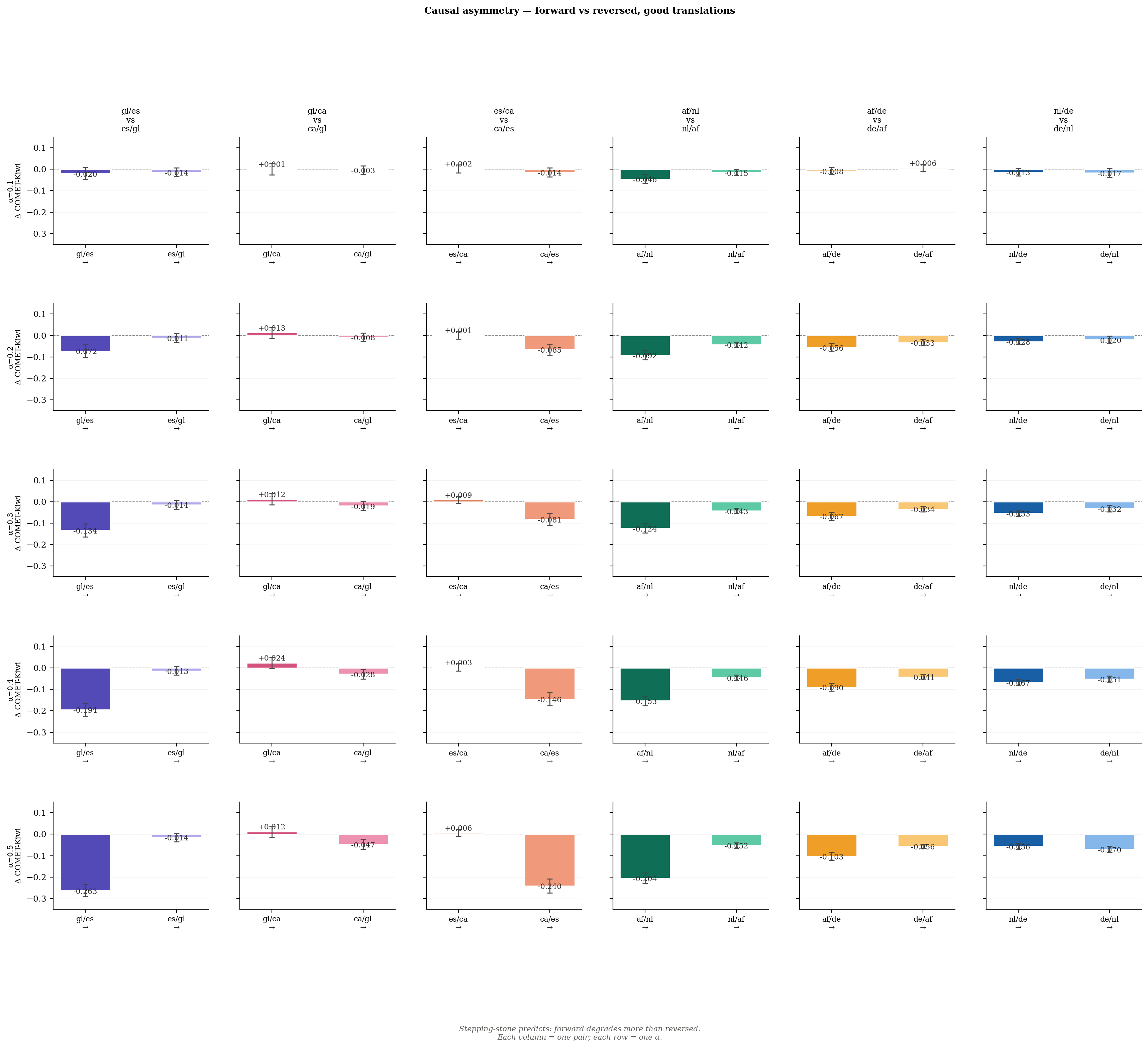
We see the forward and reversed COMET-Kiwi deltas side by side, across all five α values, for both primary families.
| Pair | Forward (α=0.5) | Reversed (α=0.5) |
|---|---|---|
| gl/es vs. es/gl | −0.263 | −0.014 |
| af/nl vs. nl/af | −0.204 | −0.052 |
| af/de vs. de/af | −0.103 | ~0.000 |
| ca/es vs. es/ca | −0.240 | ~0.000 |
| gl/ca vs. ca/gl | ~0.000 | ~0.000 |
Across both families, the pattern is consistent: suppressing the high-resource axis from low-resource hidden states (forward direction) produces substantial, monotonically increasing quality degradation, while the reversed intervention — suppressing the low-resource axis from high-resource hidden states — produces effects close to zero. This asymmetry holds at every level of α and across all primary pairs, ruling out the possibility that the degradation is simply a consequence of disrupting those particular layers. The model depends specifically on the high-resource directional component in low-resource generation, not on layer integrity in general.
In the bad translation group, overall effect sizes are attenuated across all pairs. This is the expected pattern: for sentences where the model has already failed to produce a high-quality translation, the stepping-stone pathway is likely already disrupted, and further suppression of the high-resource axis produces a smaller marginal degradation from an already low baseline. The relative ordering of pairs is nonetheless preserved, suggesting the geometric dependence contributes to quality even for sentences the model handles poorly
5.6 Anomalies
Two results resist clean interpretation and are worth flagging honestly.
First, the af/es cross-family control shows unexpectedly large forward degradation (−0.172 at α=0.5), comparable in magnitude to the primary af/de pair. The most plausible explanation is the geometric dominance of the Spanish axis — the highest-resource language in the study has the largest and most stable contrastive axis, and suppressing it from any language's hidden states, related or not, may remove energy that is incidentally aligned with a prominent direction rather than specifically dependent on it. This interpretation is supported by the near-zero reversed es/af effect: if the degradation reflected a genuine stepping-stone dependency, the reversed direction would also show degradation.
Second, the ca/es reversed direction shows anomalously large degradation at higher α values. Catalan's forward effect magnitude (−0.240) is comparable to Galician's despite its medium-resource status. This is a reminder that how much data a language has in pretraining and how close it sits to other languages in the model's hidden space are not the same thing; Catalan's geometric position appears closer to Galician's than its training data volume would suggest.
6. A Note on the Logit Lens
A parallel investigation explored whether the model's internal pivot language could be tracked layer-by-layer using the logit lens (nostalgebraist, 2020) — a technique that projects intermediate hidden states back through the language model head to infer an implied language at each depth. We attempted three operationalisations: running fasttext language identification on top decoded tokens, building per-language prototypes from seed words in the LM head weight space, and summing logit mass over per-language vocabulary partitions.
All three approaches failed. Byte-pair encoding (Sennrich et al., 2016) and SentencePiece (Kudo and Richardson, 2018) both optimise for compression across the full training corpus, producing tokens that are shared across languages. A token like _the appears in many languages; _un is shared across French, Spanish, and Italian. There is no clean partition of the vocabulary into per-language subsets. Token-level language attribution is not just difficult in this setting.
This finding ruled out logit-lens-based routing analysis as a viable approach, and led to the pivot towards subspace containment and projection-based analysis reported in this thesis. It also has direct implications for any vocabulary-based interpretability method applied to multilingual models: token-level language attribution is not just difficult in this setting — it is structurally ill-posed.
7. Research Question Outcomes
The thesis was structured around five distinct research questions, each targeting a different aspect of the stepping-stone hypothesis. The first two ask whether the geometric relationship exists and whether it is directional. The third tests causal load-bearing — the core claim. The fourth asks whether the pattern generalises across independent language families. The fifth addresses the logit lens as a complementary analysis tool. The table below summarises the outcome of each.
| RQ | Question | Outcome |
|---|---|---|
| RQ1 | Do LR languages depend geometrically on within-family HR relatives? | ✓ Confirmed |
| RQ2 | Is the dependence directional? | ✓ Confirmed |
| RQ3 | Is it causally load-bearing for generation quality? | ✓ Confirmed |
| RQ4 | Does the pattern replicate across independent families? | ~ Partial — two cross-family anomalies attributed to axis prominence |
| RQ5 | Does the logit lens reliably track language identity? | ✗ Negative — structurally ill-posed in multilingual settings |
8. Limitations
wmt22-cometkiwi-da is not a language detector. A fluent Spanish output when Galician was requested will score well on COMET-Kiwi, because the metric has no mechanism for penalising output in the wrong language. This means the ablation effects reported here are lower bounds on true causal impact — language collapse is invisible to the metric, and the reported Δ COMET values likely underestimate the true degree of disruption to low-resource generation.
Language selection is constrained by evaluation infrastructure. The stepping-stone hypothesis is most consequential for severely underrepresented languages, but those are precisely the languages for which wmt22-cometkiwi-da coverage, parallel corpora, and probing benchmarks do not exist. The results do not straightforwardly generalise beyond European languages with established NLP resources — a self-reinforcing gap that is itself a research problem.
9. Key Takeaway
Building low-resource representations that do not lean on a high-resource neighbour — that encode language-specific structure in their own right — may require more than simply adding more training data in that language. The experiments here show that Apertus-8B-Instruct-2509 develops a specific geometric scaffold — low-resource representations that borrow the structural direction of their high-resource relatives — and that this scaffold is causally load-bearing for generation quality, as shown by the monotonic dose-response curves in the forward ablation and the forward/reversed asymmetry grid, which together establish both that removing the high-resource direction degrades output and that the effect is directionally specific.
Genuinely autonomous low-resource representations may require more than data parity. The structural relationship between related languages in the model's hidden state space may need to be addressed directly: through deliberate data rebalancing within language families, through architectural choices that encourage language-specific representational development, or through fine-tuning strategies that strengthen the low-resource direction independently of its high-resource neighbour.
The languages most affected by these asymmetries are those whose speakers have the most to gain from effective language technology — and the least recourse when it fails.
10. Acknowledgements
This work was carried out as a master's thesis at ETH Zürich (IVIA Lab) and the Social Computing Group at EPFL, within the Swiss AI Initiative. I am grateful to my supervisors Prof. Dr. Daniel Gatica-Perez and Prof. Dr. Mennatallah El-Assady for providing the resources that made this work possible, to Dr. Rita Sevastjanova for her guidance on visualisation and grounded analysis, and to Dr. Anna Hedström for joining the project through the Swiss AI Initiative and for her input on the interpretability framing. Experiments were run on the Clariden HPC cluster at CSCS.
Comments
Sign in to join the conversation.
Sign in to commentNo comments yet.