Detecting and Reducing Hallucination in Multiple-Choice Questions with Activation Steering
ETH Zurich · Data Science Lab · 2026
Authors: Aleks Stepancic*, Tu Nguyen*, Eduard Durech, Anna Hedström
* Equal contribution
We study mechanistic error reduction via activation steering on the Apertus family of language models, extending the MERA framework to mixed-domain and cross-dataset settings.
1. Abstract
Large language models can be unreliable even on simple multiple-choice tasks, and mitigating such errors at inference time remains challenging. This project studies mechanistic error reduction via activation steering on the Apertus family of language models, focusing on datasets where the base model exhibits low accuracy. We evaluate training probes and steering on single datasets and then extend prior work to mixed-dataset and cross-dataset settings. Across multiple datasets and models, we observe that linear probes on mid-late layers predict errors well, and a single probe trained on a mixture of all datasets performs competitively with per-dataset probes. Calibrated Mechanistic Error Reduction with Abstention (MERA) steering improves accuracy across datasets and models, consistent with the original paper results.
2. Motivation
Despite the considerable capabilities of modern language models, they remain error-prone in many tasks. Failures arise not only in open-ended settings such as reasoning, factual consistency, or planning, but also in simple prediction tasks and multiple-choice benchmarks. Reducing such errors remains an open and important research challenge.
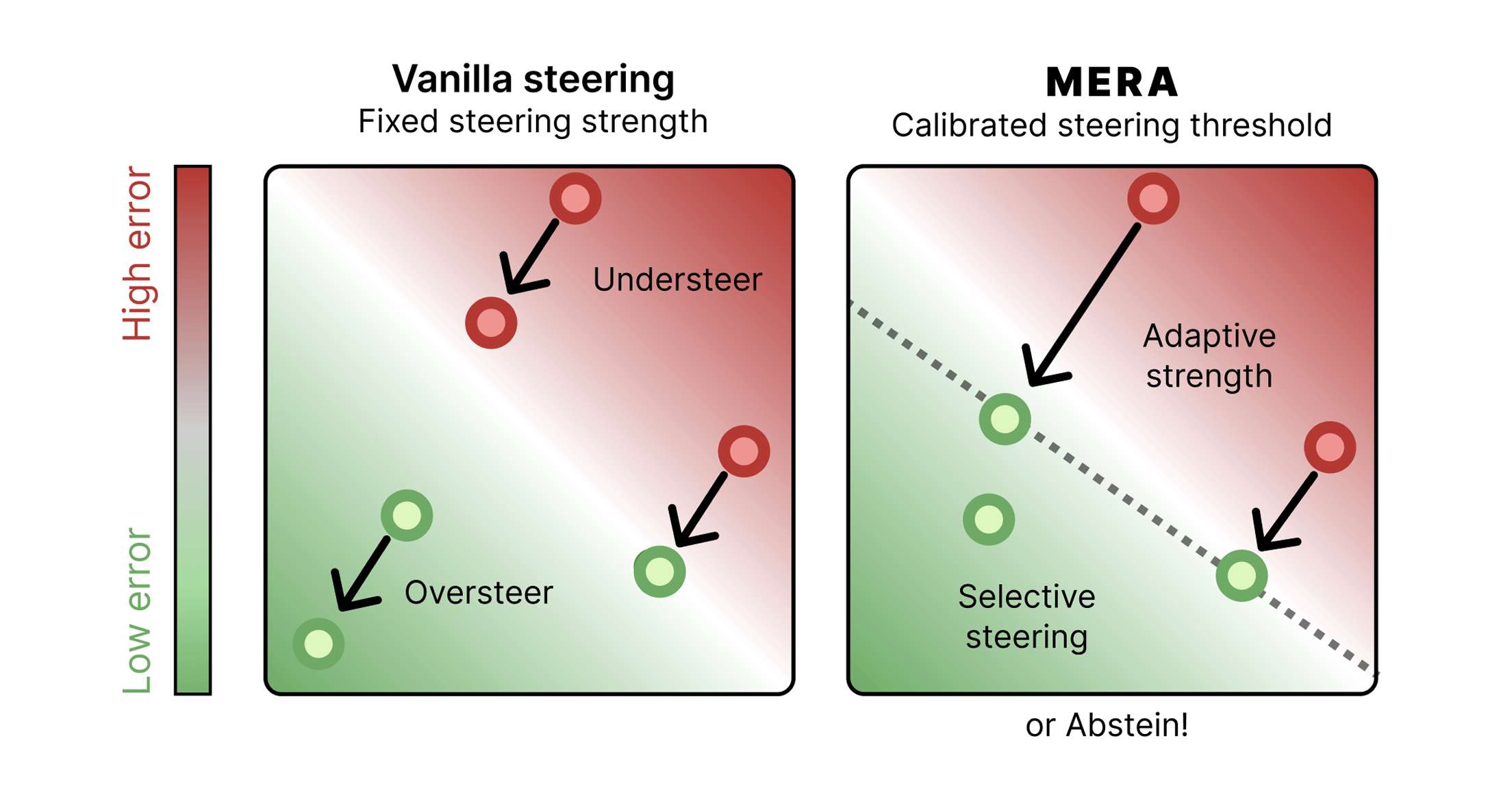
Recent work on Mechanistic Error Reduction with Abstention (MERA) proposes an inference-time framework for mitigating prediction errors. By acting on a single designated Layer L, this approach uses an Error Probe to estimate the likelihood of a mistake. Based on this prediction, it applies calibrated MERA Steering to safely intervene on the residual stream, abstaining when no reliable improvement can be guaranteed. This results in non-degrading performance while avoiding both under- and over-steering.
In this work, we apply the MERA framework to the Apertus family of language models, a family where performance gaps on reasoning benchmarks have been reported. We extend the framework in two directions: mixed-domain probe training, where error-estimation probes are trained on heterogeneous datasets, and cross-dataset steering, where probes trained on one domain are used to steer on another.
3. Contributions
- We reproduce the MERA framework on the Apertus model family, confirming that calibrated steering improves accuracy on datasets where the base model performs poorly.
- We evaluate cross-dataset probe generalisation systematically, revealing structured but limited transfer between task domains.
- We train error-estimation probes on a mixture of all datasets and show that mixed-domain probes perform competitively with per-dataset probes, producing more robust error representations.
- We adopt a normalised Steering Performance Impact (SPI) metric inspired by prior work that enables fair comparison across tasks with different baseline accuracies.
4. Problem Setup
4.1 Task
We consider autoregressive, decoder-only transformer language models evaluated on supervised multiple-choice and binary classification tasks. For each input prompt, the model produces hidden activations across layers. We evaluate logits at a selected token position: either the last token (final input token) or the exact token (first generated token matching a valid label).
Given logits at token position , the predicted label and its normalized probability are defined as:
We define a continuous error signal:
where is the normalised probability assigned to the correct answer.
4.2 Models
We evaluate both base and instruction-tuned variants of two model families: Apertus-8B and Apertus-8B-Instruct (our primary focus), alongside Llama-3.1-8B and Llama-3.1-8B-Instruct for cross-family comparison. All models have 32 transformer layers.
4.3 Datasets
We evaluate on six benchmarks spanning reasoning, scientific knowledge, and text classification:
| Dataset | Domain | Samples |
|---|---|---|
| MMLU High School | MCQA / Reasoning | 3,790 |
| MMLU Professional | MCQA / Reasoning | 3,220 |
| ARC-Challenge | MCQA / Science | 2,590 |
| ARC-Easy | MCQA / Science | 4,626 |
| SMS Spam | Text Classification | 5,574 |
| Yes-No Finance | Finance | 5,000 |
MCQA = multiple-choice question answering.
5. Method
Our pipeline consists of four stages: (1) activation extraction, (2) probe training, (3) steering strength calibration, and (4) inference-time steering. For each model and dataset, we cache hidden-state activations at every transformer layer during inference. Linear probes are then trained to predict model error from these activations. At inference time, the probe weights define steering directions, while a calibrated threshold determines when and how strongly to intervene.
5.1 Probe Training
We train linear probes of the form , where denotes activations at a given layer and token position. Probes are trained using supervised regression to predict the continuous error . We compare two probe types:
- Linear probes (L-$\alpha$): ridge regression with regularisation strength , directly regressing onto the error signal.
- Logit probes (Logit-L-$\alpha$): logistic regression mapping activations to a probability of error.
Probe quality is measured using root mean squared error (RMSE) between predictions and ground-truth error. Lower RMSE indicates more accurate error estimation and potentially a more reliable steering signal.
5.2 Steering Methods
We compare four inference-time steering strategies:
- Prompt steering: task instructions injected into the input text. Serves as a no-access baseline.
- Additive steering: fixed-strength addition of probe weights to activations.
- Contrastive steering: a non-calibrated baseline that steers along the difference-of-means direction between activations from correct and incorrect examples.
- MERA (calibrated steering): optimally calibrated intervention that steers only when the predicted error exceeds a threshold , with strength proportional to the error magnitude. For linear probes, this yields a closed-form solution: We also evaluate a MERA logistic variant using logit probes. Steering is applied across mid-to-late layers following probe performance trends.
- MERA contrastive: a calibrated variant of contrastive steering. Instead of using probe weights as the steering direction, it uses the contrastive correct-vs-incorrect direction, while still applying the MERA thresholding and abstention rule to decide when to intervene.
6. Results
6.1 Probe Quality Across Layers
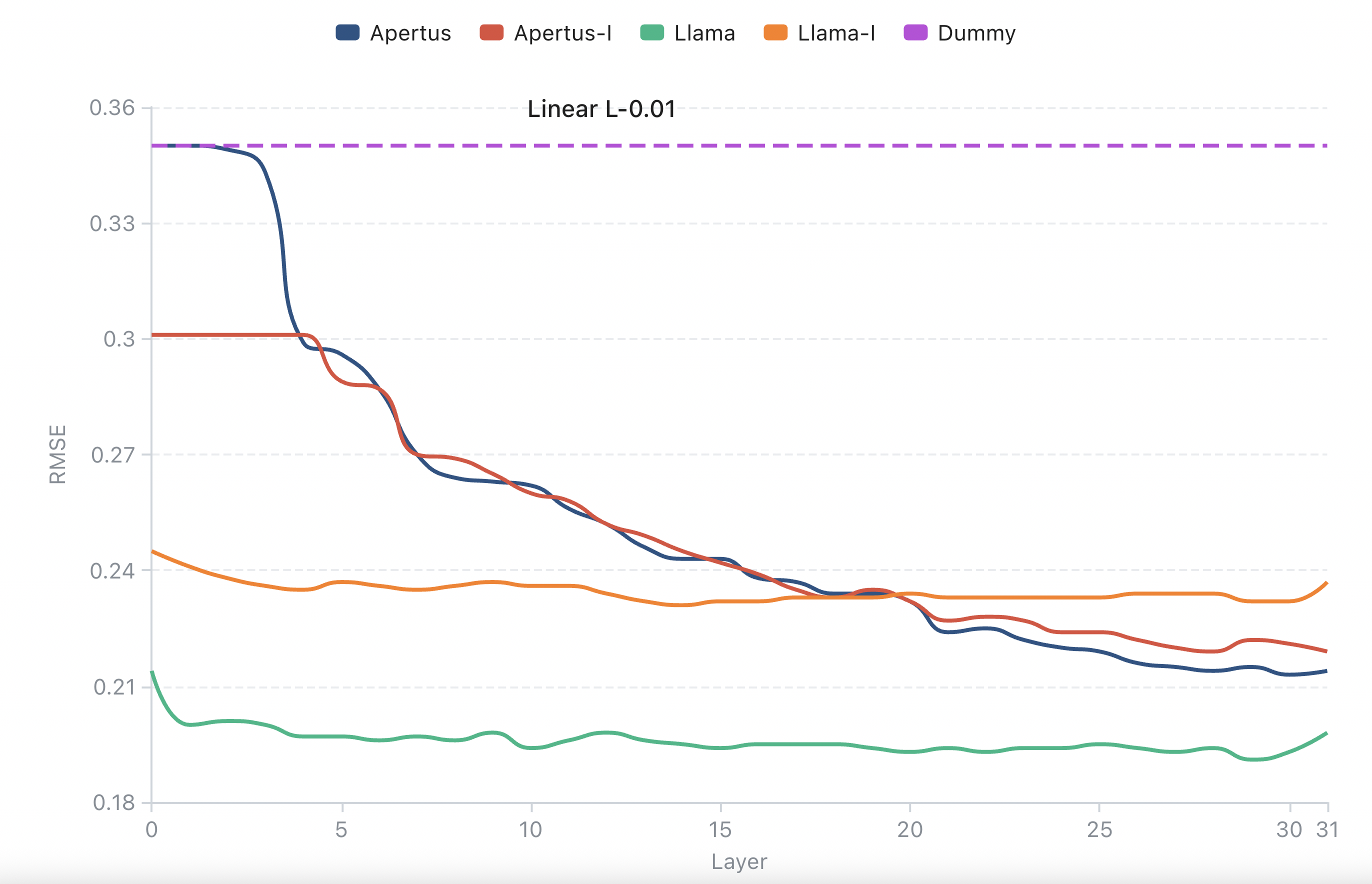
Linear probes achieve low RMSE in mid-to-late layers across datasets and models, indicating that transformer activations contain a usable continuous error signal. The strongest probe performance typically appears in intermediate-to-late layers, where RMSE falls well below the dummy baseline. Figure Figure 1 shows the layer-wise RMSE of L-0.01 linear probes across base and instruction-tuned Apertus and Llama models.
6.2 Cross-Dataset Generalisation
Cross-dataset evaluation reveals that error probes exhibit limited but structured generalisation. Probes trained and evaluated on the same dataset consistently outperform cross-dataset probes, confirming that error representations are partially domain-specific. However, datasets with similar task structures (e.g., MMLU High School and MMLU Professional) show relatively strong cross-generalisation. Probes trained on ARC-Easy generalise well to both ARC-Challenge and MMLU benchmarks, suggesting its mixture of factual recall and lightweight reasoning produces a more transferable error signal. Figure 2 and Figure 3 show these patterns.
6.3 Steering Performance
We report steering results using the exact token position across all models and datasets. Performance is measured using Steering Performance Impact (SPI), a normalised metric bounded in that captures relative improvement scaled by the remaining performance headroom. Here, denotes the original unsteered accuracy on the test dataset, and denotes the accuracy after applying steering:
A value of SPI = 0 indicates no effect; positive values indicate improvement.
The dataset-specific steering results show positive SPI for both linear and logit-probe MERA in several settings. Linear MERA gives the largest gain on SMS Spam, while logit-probe MERA is competitive on datasets such as MMLU High School and ARC-Easy. Overall, the effect is dataset-dependent rather than uniform across all benchmarks. See Figure 4 and Figure 5.
6.4 Mixed-Dataset Robustness
We investigate two extensions to assess robustness: mixed-dataset probe training and cross-domain steering. Training probes on a mixture of all datasets consistently improves error prediction quality across layers for both model families, as previously seen in Figure 1. Mixed-training probes achieve RMSE values substantially below the dummy baseline, indicating that the probe captures non-trivial error structure rather than dataset priors alone.
For Apertus-Instruct, mixed training reduces RMSE relative to single-dataset probes across most layers, with the strongest gains in middle layers. The gap between Llama and Apertus narrows under mixed training, indicating that dataset diversity partially compensates for weaker baseline calibration. Increasing the probe learning rate from 0.02 to 0.05 leads to uniformly higher RMSE, suggesting that overfitting to heterogeneous error patterns degrades generalisation. Figure 6 shows the mixed-dataset probe results.
The final set of results evaluates steering vectors trained on mixed datasets and applied to individual target benchmarks. Mixed training yields robust positive SPI on SMS Spam, even when the target dataset constitutes only a fraction of the training mixture. On other benchmarks, mixed steering is largely neutral, avoiding severe degradations. See Figure 7.
7. Limitations
- All experiments are conducted on 8B-parameter models. It remains unclear whether these findings transfer to larger or smaller architectures.
- We focus on multiple-choice and binary classification tasks. Open-ended generation tasks may exhibit different error structure.
- Steering relies on access to internal activations, which limits deployment in black-box settings.
- The SPI metric, while normalised, may mask absolute accuracy differences when baseline performance is very high or very low.
- Mixed-dataset steering trades peak per-task performance for robustness, which may not be desirable in all deployment scenarios.
8. Conclusion & Future Work
We reproduced and extended the MERA framework on the Apertus family of language models. Linear probes capture error-related signals consistently across layers, while logit-based probes are less stable and less informative. Calibrated linear steering improves performance on tasks where the base model performs poorly, especially on SMS Spam, and avoids the large performance drops seen with contrastive and fixed-strength baselines.
Training probes on mixed datasets leads to more stable behaviour across domains, though the gains are smaller than task-specific steering. Mixed-domain steering shows that cross-domain probes can still produce positive effects, but improvements are weaker and more task-dependent. Overall, MERA is a reliable and safe method for inference-time error reduction, particularly when base model accuracy is low.
Future work includes extending these experiments to larger models (70B+), evaluating on open-ended generation tasks, investigating non-linear probe architectures, and studying the interaction between activation steering and other inference-time techniques such as guided decoding.
9. Code Availability
Associated code is available open-source and under the MIT License, which permits free reuse, free modification, and free distribution, provided proper attribution is given to the authors, and no liability is assumed by the authors. The code and its MIT license are publicly available at github.com/swiss-ai/apertus-probes.
Stepancic, Nguyen, Hedström, Durech. ETH Zurich, 2026.
Comments
Sign in to join the conversation.
Sign in to commentNo comments yet.