Benchmarks for Apertus - Our Evaluation Pipeline & Lessons Learned
Alexander Sternfeld and Yannick Metz, May 2026
Evaluation is how we find out what a model has actually learned. Before any mechanistic story about why a model behaves a certain way, we need a reliable account of what it does, and benchmarks are our primary instrument for that. The goal of this post is to share what we learned evaluating Apertus, a natively multilingual open model built within a broad consortium. Some lessons surprised us: "temperature 0" generation is not deterministic, a driver update can move a score by several percent, and the single most valuable habit is reading raw model outputs rather than trusting aggregate scores. Concretely, we first give an overview of the benchmarks used in developing and evaluating Apertus, then discuss our evaluation harness for internal benchmarking, and finally highlight the challenges we faced. We plan to deep-dive on additional topics (such as agentic evaluations, choice of inference framework, and alignment benchmarks) in future blog posts.
1. Benchmarking LLMs
Evaluating general-purpose LLMs such as Apertus is challenging: we want to measure the effectiveness of the models in a broad range of topics and application areas, and Apertus specifically is designed as a natively multilingual model. Furthermore, the pre-training and post-training stage require different benchmarks, because a base model cannot follow instructions and must be probed with completion-based tasks, while a post-trained model can be evaluated on instruction-following tasks. Thus, we collect and organise tasks in terms of benchmark categories, picking benchmarks that complement each other within a category, and then making sure that the categories together cover the things we actually care about.
1.1 Categories of benchmarks
During the pretraining stage, the question is whether the base model has acquired sensible general knowledge and abilities based on its training data. Therefore, the first category of benchmarks covers general language understanding, which looks at sentence-level reasoning, common sense, natural language inference, and basic causal reasoning. The second category is factual knowledge, which we further separate into language-agnostic knowledge (the kind of facts that hold regardless of language) and region-specific knowledge (cultural and geographical content tied to particular communities).
At the post-training stage, we add several new categories that only make sense once the model can follow instructions:
- Knowledge recall is closer to an exam-style assessment, asking whether the model can retrieve and apply factual information when prompted.
- Instruction-following measures how well the model actually does what it is told, including formatting and constraint compliance.
- Reasoning covers multi-step problems that go beyond simple recall.
- Math and coding are kept as their own categories because they have distinct evaluation protocols (executable verifiers for code, numerical answer checking for math) and because performance on them tends to be loosely coupled with performance elsewhere.
- Cultural knowledge becomes its own category at this stage as well, since it benefits from the model being able to give free-form answers in the target language.
- Safety evaluations were run as a separate set covering bias, toxicity, harmful content, and multilingual safety.
- Long context was evaluated separately, where the extended-context variants of the model were assessed.
Table 1 below summarizes the benchmarks that we used per category.
| Category | Benchmarks |
|---|---|
| General language understanding (pretraining) | HellaSwag, ARC, WinoGrande, XNLI, XCOPA, PIQA |
| Factual knowledge, language-agnostic (pretraining) | MMLU, Global-MMLU |
| Factual knowledge, region-specific (pretraining) | INCLUDE, BLEnD, CulturalBench, SwitzerlandQA |
| Knowledge recall (post-training) | AGIeval, MMLU, Global-MMLU, TruthfulQA, TruthfulQA Multilingual |
| Instruction following | IFEval, Multi-IFEval, AlpacaEval |
| Commonsense reasoning | HellaSwag, HellaSwag Multilingual |
| Reasoning | BBH, DROP, ACPBench (Bool, MCQ), ARC Challenge, GPQA, MLogiQA |
| Math | GSM8K, GSM8K-Platinum, Hendrycks MATH, MathQA, MGSM |
| Coding | HumanEval, MBPP |
| Cultural knowledge | INCLUDE, INCLUDE V2, BLEnD, CulturalBench, SwitzerlandQA |
| Long context | RULER (4k to 64k) |
| Translation (low-resource) | Romansh WMT24++ |
| Safety and bias | BBQ, ToxiGen, HarmBench, RealToxicityPrompts, LinguaSafe |
Table 1. Evaluation benchmarks used for the training of Apertus 1, separated by category
1.2 Choosing complementary benchmarks
One might expect the community to have converged on a fixed benchmark suite that every team simply runs, but no such standard exists, and each team re-picks. There are a few reasons. Benchmarks saturate and leak: once a test is widely used, scores climb toward the ceiling and the data often ends up in training sets, so the informative set keeps shifting over time. Shared leaderboards have not settled the question either. The Hugging Face Open LLM Leaderboard, for years the default reference, was retired in 2025 in part out of concern that it encouraged teams to hill-climb on a narrow set of metrics, and because the benchmarks were not keeping pace with new model capabilities. Any fixed suite also reflects the priorities of whoever built it, and for a natively multilingual model like Apertus the common defaults leave out much of what we care about, such as cultural and low-resource-language coverage, so curation is unavoidable.
Examples in the general language understanding category, used during pre-training, are HellaSwag and PIQA, which both look like multiple choice commonsense tasks, with HellaSwag being about continuation plausibility while PIQA targets physical commonsense. ARC adds science knowledge, WinoGrande focuses on coreference, XNLI adds entailment, XCOPA adds causal reasoning across languages. The set spans different kinds of reasoning rather than testing the same facet too many times. The same principle drove the split between language-agnostic and region-specific factual knowledge: doing well on MMLU is not the same as doing well on CulturalBench or SwitzerlandQA, and lumping them together would let strong English performance hide weak cultural coverage.
We also held out a subset of benchmarks (AGIeval, ARC Challenge Chat, ARC Challenge Multilingual, GPQA Main, GSM8K Platinum, MLogiQA) from the development loop, so the final numbers act as a sanity check that we did not overfit our decisions to the metrics we were observing during pre- and post-training.
2. Evaluation Harnesses
An evaluation harness is the machinery that runs a set of benchmarks against a model in a consistent way. The harness handles the data set loading, prompt formatting (including a few-shot sample), calling the model, post-processing of the output, and aggregation of results into final metrics. From the user's perspective, evaluating a model on a set of benchmarks becomes a single command. From a research perspective, it means that two different teams running the same benchmark on the same model should, in theory, get the same number.
There are several harnesses in active use today. EleutherAI's lm-evaluation-harness is probably the most widely cited and is the backend behind the original Hugging Face Open LLM Leaderboard. BigCode has a separate harness focused on code generation tasks. Stanford's HELM project takes a broader view and tries to evaluate models across many dimensions in a single coordinated framework. More recently, there are framework-specific evaluation pipelines built into libraries like lighteval and into vendor toolkits. Each makes slightly different design tradeoffs around speed, configurability, the supported model backends, and how easy it is to write new tasks. For a deeper discussion of these challenges and the design choices, we refer to the paper introducing the `lm-evaluation-harness`
Beyond reproducibility, harnesses earn their keep on operational grounds as well. Running an evaluation on a 70 billion parameter model across dozens of tasks is not cheap, and a naive script will leave a lot of throughput on the table. Modern harnesses integrate with fast inference backends like vLLM or SGLang, support multi-GPU and data-parallel execution, batch requests intelligently, and cache intermediate results so that a crash partway through a long run does not mean starting over. They also tend to ship integrations with experiment trackers so that runs are logged, results are diffed across model versions, and individual model outputs can be inspected when a number looks suspicious.
3. EleutherAI LM Evaluation Harness
For Apertus benchmarking, we chose Eleuther AI's lm-eval harness due to it being widely adapted, fully open source, with support of many inference frameworks and models. We adopted lm-eval-harness during benchmarking of Apertus 1.0, around July 2025. While the framework matured parallel to development, we initially had to integrate a series of changes, especially in terms of response parsing and caching, which led to a custom fork of lm-eval-harness. This is discussed in more detail in Section 4, Challenges Faced.
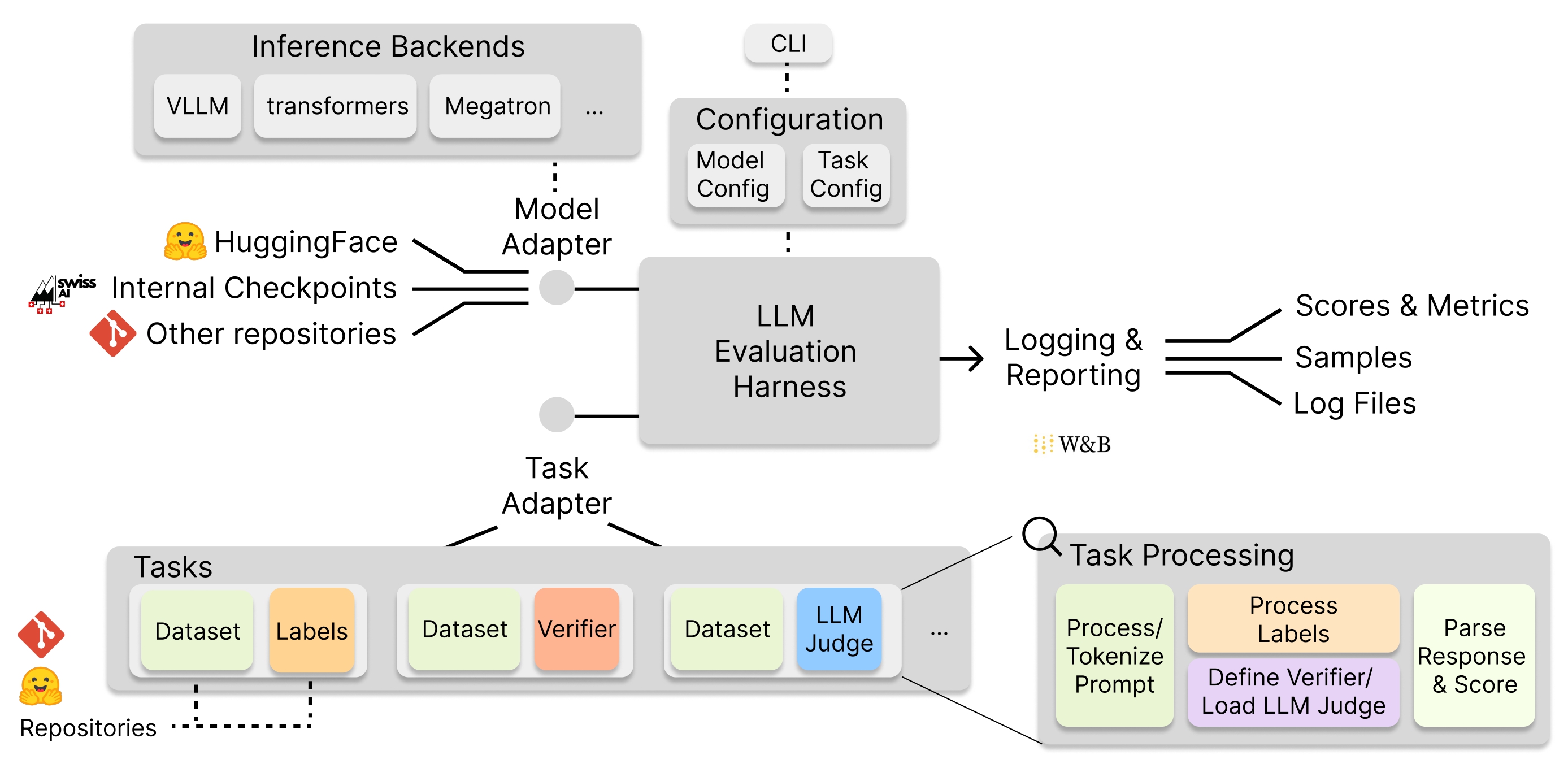
Figure 1 highlights the basic elements of an evaluation harness: Model Integration, Task Integration, Configuration, and output logging. The harness serves as a framework to integrate various models, loaded from different repositories - primarily Huggingface and our own internal training checkpoints. Crucially, lm-eval-harness supports different inferece backends: vLLM (our go-to framework), native HF transformers, and recently Megatron-LM, which allowed us to benchmark our internal models without conversion. Importantly, the harnesses should match the relevant settings between the models, such as maximum output tokens and temperature. Still, we have identified that scores may differ between inference backends (more on that in a future blog post). If not reported otherwise, we always report scores from a single inference backend framework (vLLM), e.g. in our tech report, to allow for a direct head-to-head comparison.
The most important role of the harness is to integrate all relevant tasks/benchmarks via a common interface. Each task has its own dataset that contains questions / answers, ground-truth labels, or information necessary for task verification. Beyond sampling parameters like temperature, the harness also builds standardized prompts, relevant both for instruction-tuned models and base models.
Let us look at the processing pipeline for one benchmark (MMLU) that we use in our benchmarking:
The raw MMLU dataset contains records that consist of several components:
The question:
The earthen monument called Mound 72 contained the burials of more than 270 people, including an adult male interred on a platform with 20,000 conch-shell beads in the shape of a giant bird. Mound 72 represents the most complex ______ society at ________.The list of answering options: (
['Ancestral Puebloan; Pueblo Bonito', 'Hohokam; Casa Grande', 'Mississippian; Cahokia', 'Adena; Snaketown.'])The label, which is the index of the correct anser:
2Metadata, which for MMLU is the category:
prehistory
This raw record is then transformed into a prompt template:
<s><|system_start|>The following are multiple choice questions (with answers) about prehistory. Your response should be concise, and you should end with "The answer is (X)", where X is the correct letter choice.
<|system_end|><|developer_start|>Deliberation: disabled
Tool Capabilities: disabled<|developer_end|><|user_start|>Q: The earthen monument called Mound 72 contained the burials of more than 270 people, including an adult male interred on a platform with 20,000 conch-shell beads in the shape of a giant bird. Mound 72 represents the most complex ______ society at ________.
(A) Ancestral Puebloan; Pueblo Bonito (B) Hohokam; Casa Grande (C) Mississippian; Cahokia (D) Adena; Snaketown.
Let's think step by step.<|user_end|><|assistant_start|>This particular prompt follows the recommendation of the benchmark authors (Hendrycks et al., 2021). However, teams might choose different few-shot formulations that may account for score differences. Using a harness, we keep scores comparable. As mentioned, we need to choose a sampling configuration for our model, for instance, a temperature of 0 to only choose the most likely answer. Let us look at a raw model response:
[['The answer is (C) Mississippian; Cahokia.
Step-by-step reasoning:
1. The earthen monument Mound 72 is associated with the Mississippian culture.
2. The Mississippian culture is known for its complex societies, which are characterized by large earthen mounds and elaborate burials.
3. Cahokia is a well-known Mississippian site in present-day Illinois, which includes Mound 72.
4. The other options are incorrect:
- (A) Ancestral Puebloan; Pueblo Bonito refers to the Ancestral Puebloan culture and the Pueblo Bonito site in Chaco Canyon, New Mexico.
- (B) Hohokam; Casa Grande refers to the Hohokam culture and the Casa Grande site in Arizona.
- (D) Adena; Snaketown refers to the Adena culture and the Snaketown site in Ohio.']]The model answered correctly, but provided a long free-text answer that is not trivial to interpret within an automated evaluation framework. We therefore must parse the response and perform a matching step to extract the actual response that can be compared to the ground-truth label. Each task in lm-eval-harness thus provides a response parsing (matching) function, in this case an exact-match against a regular expression is performed. LM-eval-harness specifies a regular expression to perform the extraction:
"((?<=The answer is )(.*)(?=.)|(?<=answer is )(.*)(?=.)|(?<=The answer: )(.*)(?=.)|(?<=The final answer: )(.*)(?=.))"
Note that we have specified this response format in the initial prompt to the model, which enables this deterministic parsing. The regex specifies to only take the first matching occurrence. Therefore, in our case, the output of the match is the letter C which can be directly compared to the label C. We hope that this example provided a glimpse into the challenges we face when conducting a robust evaluation of models.
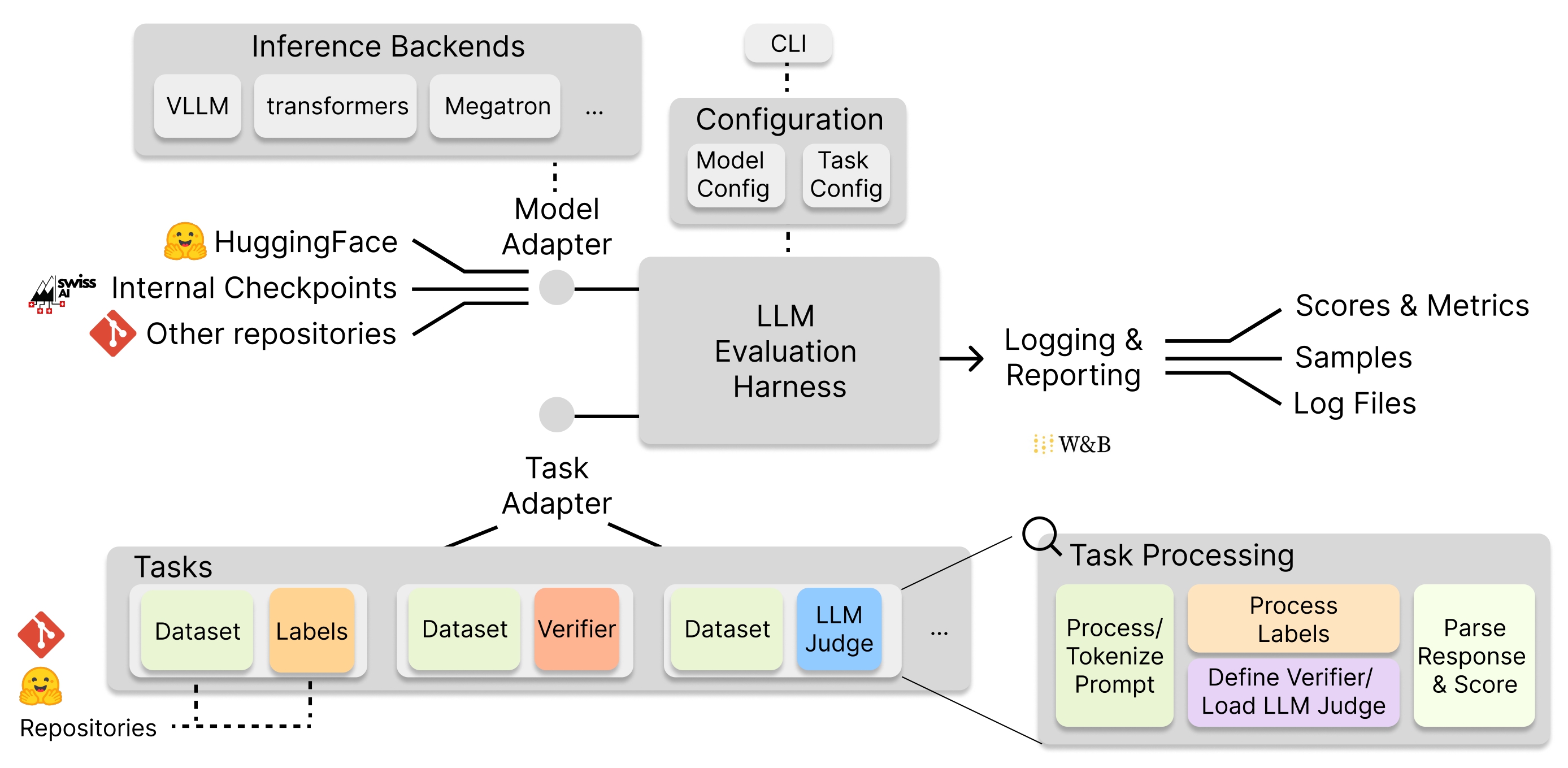
Going beyond multi-choice benchmarks, we increasingly rely on programatic verifiers (like unit tests) for coding specifically, and LLM judges for more free-form responses. We have integrated these in our implementation of eval harness. We have highlighted this task processing (including prompt construction, label and response parsing) in Figure 2.
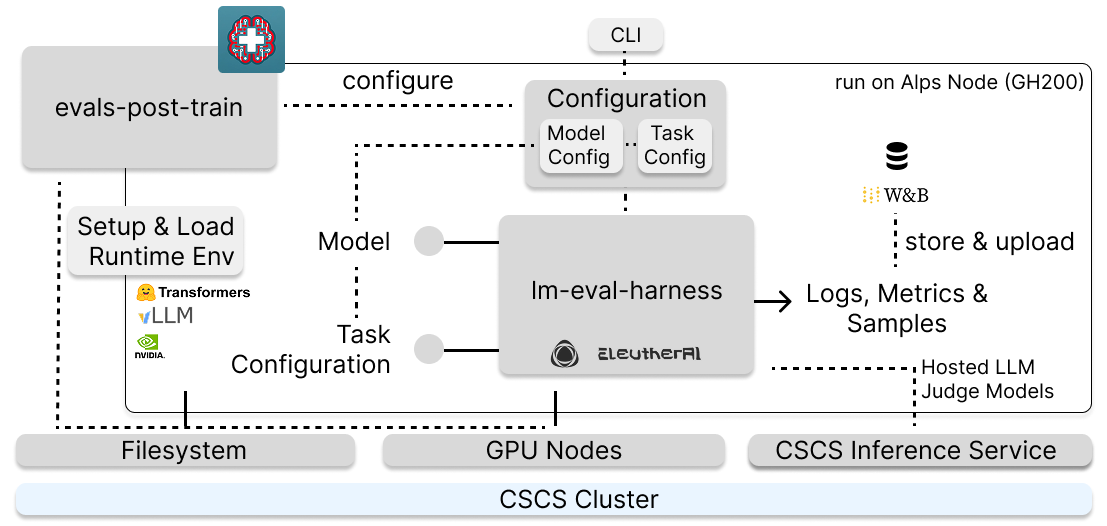
We collect all benchmark results in a centralized Weights and Biases repository. Here, we log metrics, but importantly raw samples (e.g., 10 samples per benchmark) as well, which allows for a quick inspection of prompts, solutions, and model responses. The upload to Weights and Biases, as well as configuration, environment variables, and importantly loading of the correct runtime environment (dependencies for VLLM, transformers, CUDA, ...) are handled by our eval-post-train repository (Figure 2). We run our model evaluations on GH200 nodes of our Alps compute cluster, which also hosts LLM models as API inferece endpoints - which we use in our LLM-as-a-judge benchmarks. The launch of evaluation runs can be done via a single fixed CLI command.
4. Challenges Faced
4.1 Running harnesses in an HPC cluster
The first challenge was the infrastructure itself: getting the stack to run on an ARM-based (aarch64) cluster where many x86 Python wheels do not work, and fitting long evaluation suites inside SLURM's per-job time limit. Apertus runs on Alps, the supercomputer operated by CSCS. Each node has four NVIDIA GH200 Grace Hopper Superchips, and the Grace CPU is ARM-based (aarch64) rather than the x86_64 you would assume by default. Many Python wheels on PyPI are built for x86_64 only, so a pip install that works fine on a workstation will quietly fail or fall back to a slow pure-Python build on Alps. We hit this with a handful of dependencies of lm-eval and vLLM, and the fix was either to find an ARM build, build from source inside the container, or pin a different version. The container images we ship with evals-post-train exist partly to make these decisions once and freeze them, so individual users do not have to rediscover them.
The other defining constraint is the scheduler. Jobs on Alps run under SLURM and the default time limit on our partition is 12 hours per job. A long evaluation suite, especially on a 70B model, does not necessarily fit in 12 hours. Running the full default suite (around 40 tasks) on a 70B can easily exceed the wall clock. The wrapper handles this by supporting task splitting. With --splits K, the launcher submits K parallel SLURM jobs, each running a disjoint subset of the task list, plus an aggregation job with a SLURM --dependency=afterok so it only runs once all K splits succeed. The aggregation step merges the per-split result files together with the sample JSONL files, then uploads a single combined run to W&B. This makes wall-clock time the variable that scales with cluster availability, rather than total throughput. There is also some race-condition handling we had to be careful about: only the aggregation job uploads to W&B, not the individual splits, so we do not get conflicting wandb.init calls trying to resume the same run from different nodes.
4.2 Replication
A second challenge was keeping reference numbers reproducible over time, against constantly changing libraries, evolving cluster drivers and CUDA versions, and the fact that even temperature-0 generation is not truly deterministic under batched inference. There are multiple causes of variation, which one has to take into account and manage. The first is library churn. The evaluation stack involves lm-evaluation-harness, vLLM, transformers, the tokenizer library, and a long tail of smaller dependencies, many of which are under active development. On generation-heavy benchmarks, a small change in a library can shift the final result by a few percent. Pinning version strings in a requirements file helps, but for a multi-year project where new bug fixes and features genuinely matter, you inevitably have to update packages periodically.
The second is the cluster itself. Alps is a shared, evolving system, where NVIDIA drivers and CUDA versions get updated. Following such changes, the same evaluation script can produce significantly different numbers. We saw this with vLLM in particular, where the same vLLM version against the same model can give subtly different outputs across container rebuilds.
Last, even within a single fixed environment, LLM generation at temperature 0 is not actually deterministic. When vLLM batches requests together for throughput, the exact shape of the batch affects how the underlying matmul and attention kernels are executed on the GPU. The same logical computation, performed with a slightly different batch layout, can produce slightly different logits. Most of the time these differences are too small to change the argmax over the vocabulary, but every now and then they do, and once one token diverges, the rest of the generation goes its own way. We saw this directly: re-running the same evaluation on the same checkpoint with the same backend can give different numbers.
There are things we do to keep control: we pin harness commits and dependency versions where we can, and we log enough metadata in W&B that we can later tell whether two numbers came out of the same stack. Beyond that, we have come to accept that small differences are part of benchmarking on a real system, and the right response is to be honest about the noise floor.
4.3 Parsing of Responses
A third challenge was response parsing, where correct answers were scored as wrong because hand-crafted extraction regexes failed on small formatting differences like extra spaces or newlines, which taught us to always inspect raw samples rather than trust aggregate scores alone. During initial benchmarking of Apertus, we noticed that some benchmark scores were unexpectedly low. During manual inspection of model responses, we found that the model did not adhere to an expected format in any case, e.g. adding newline characters or spaces. Many tasks in the LM evaluation harness rely on hand-crafted extraction functions, generally based on regular expressions. In effect, simple regular expressions might not match responses, even if the answer is correct. This includes likelihood-based tasks, free-text output, and coding benchmarks. We therefore modified several response extraction functions, often adding robustness against newline characters or spaces. One of the most crucial lessons during model evaluation has been the inspection of actual raw samples instead of just aggregated scores to find error sources like parsing errors or mis-match.
4.4 Judge LLM benchmarks
A last challenge we faced was the compatibility of the LM Evaluation Harness with benchmarks that utilize LLMs as a judge. For free-form outputs with no clean label, grading falls to a judge, either human or LLM. Human raters are the gold standard but do not scale and require native speakers per language, a real constraint for low-resource languages like Romansh. Benchmarks with LLMs as a judge are increasingly more common, especially for safety and alignment evaluations. To illustrate, Harmbench, Multijail, Realtoxicityprompts and Aya redteaming all use a LLM as a judge for the evaluation of harmfulness of the response.
While the LM Evaluation Harness has optimized the generations of the model that is being evaluated, it does not yet support efficient usage of a LLM as a judge. In fact, the whole evaluation component is built around sequential evaluation, taking one pair of (prompt, generation) at a time. For an efficient evaluation phase, we needed to batch the generations before sending them to the LLM judge, which was incompatible with the LM Evaluation harness evaluation stage. In the end, we managed to make it work by moving the LLM judge API calls to the metric aggregation stage, where we could implement the batching. Although the aggregation stage is meant for only combining the individual evaluations, this design choice allows us to avoid a major change in the architecture of the LM Evaluation Harness.
5. Key takeaways
- Curation is unavoidable. No standard suite exists, so we grouped tasks into complementary categories and held some out to guard against overfitting.
- Multilingual coverage must be designed in. English-centric defaults miss the cultural and low-resource-language evaluation that matters most for Apertus.
- A harness makes numbers comparable across models, versions, and inference backends, which is the only way head-to-head scores mean anything.
- Real systems have a noise floor. Library, driver, and batching effects move scores; pin what you can, log metadata, and be honest about the rest.
Comments
Sign in to join the conversation.
Sign in to commentNo comments yet.